公開日:2018-09-10
夏が終わり涼しくなるかと思ったら、台風や地震で大変な日本列島ですが、皆さまはいかがお過ごしでしょうか。
JAWS-UG沖縄のイベント「試してみよう!機械学習ハンズオン 2018年08月」に参加してきたので(もちろん、PowerBudget で!)今さらですが、少し振り返ってみたいと思います。機械学習なんてチンプンカンプン?な方にも目を通していただければ嬉しいです。
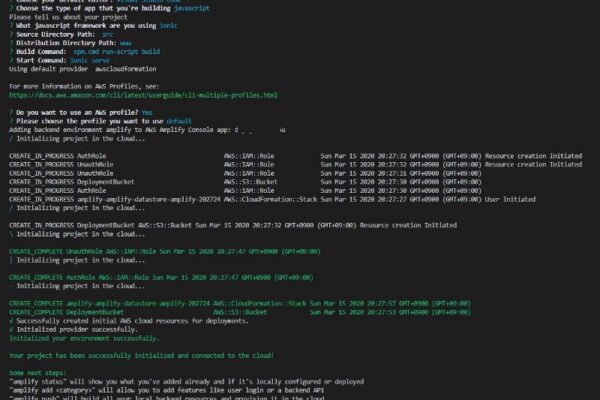
Amazon SageMaker は AWSが現在最も力を入れているサービスの一つであることは間違いありません。今回のハンズオンでは AWSJより公開されている資料に沿って、一つずつ手順を試していきました。
まず、 Amazon SageMaker とは何か、大雑把に言えば SageMaker は
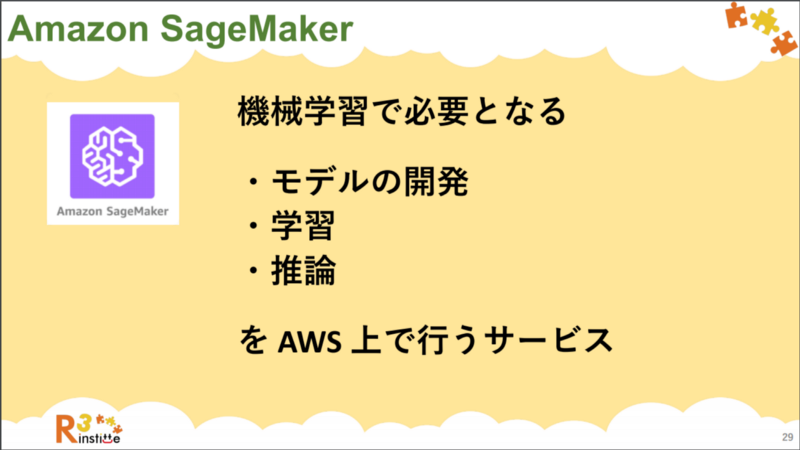
機械学習を行う上で必要な
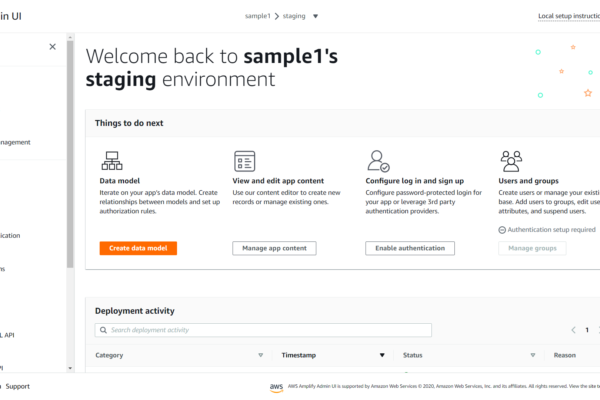
1. モデルの開発
2. 学習
3. 推論
の 3つのプロセスを AWS 上で行うためのプラットフォームです。(ハンズオンで使った資料の 始めの 10数ページあたり)
まずは 1. モデルの開発 から
Amazon SageMaker では、データ・サイエンティストの方がモデルの開発を行うための環境として、Jupyter Notebook のホスティングサービスを提供しています。
Jupyter Notebook はインタラクティブに Python のコードを実行できる大変便利な環境で、弊社では kintone のデータを取得・加工する際に使用することがあります。
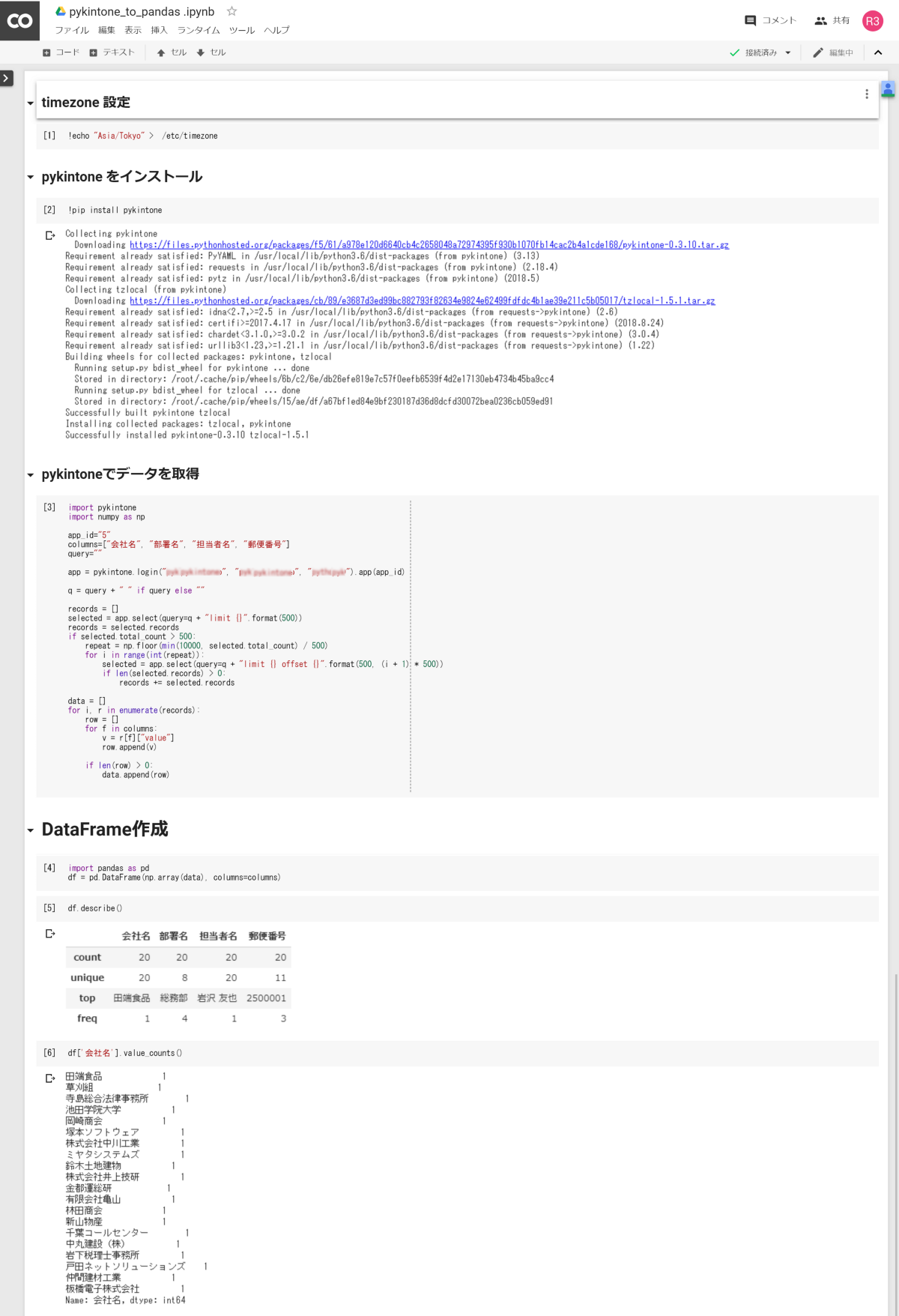
kintone のデータを取得して DataFrame を作成する例
一般的に、データ・サイエンティストの方は、ご自身のパソコン上で(手慣れたツールを駆使しながら)モデルの開発と学習(試行錯誤)を行うことが多いですが、これを Web(AWS)上で行えるようにしています。
SageMaker は人気の高い TensorFlow や Chainer、PyTorch 等々、各種の機械学習フレームワークをサポートしており、自分のパソコンの環境に依存することなしに Web上で モデルの開発を進めることが出来ます。これにより、データ・サイエンティストの PCでは動作するのに 別の環境の PCでは動作しないといった環境依存の問題を避けられます。
また、 SageMaker では
import sagemaker
sess = sagemaker.Session()
role = get_execution_role()
bucket = sess.default_bucket()
と記述すれば `sagemaker-<リージョン名>–<AWSアカウント番号>` という名前のバケットへの参照を取得できます。各種データや 開発したモデルを S3 に置くことにより、容易に共有することができます。
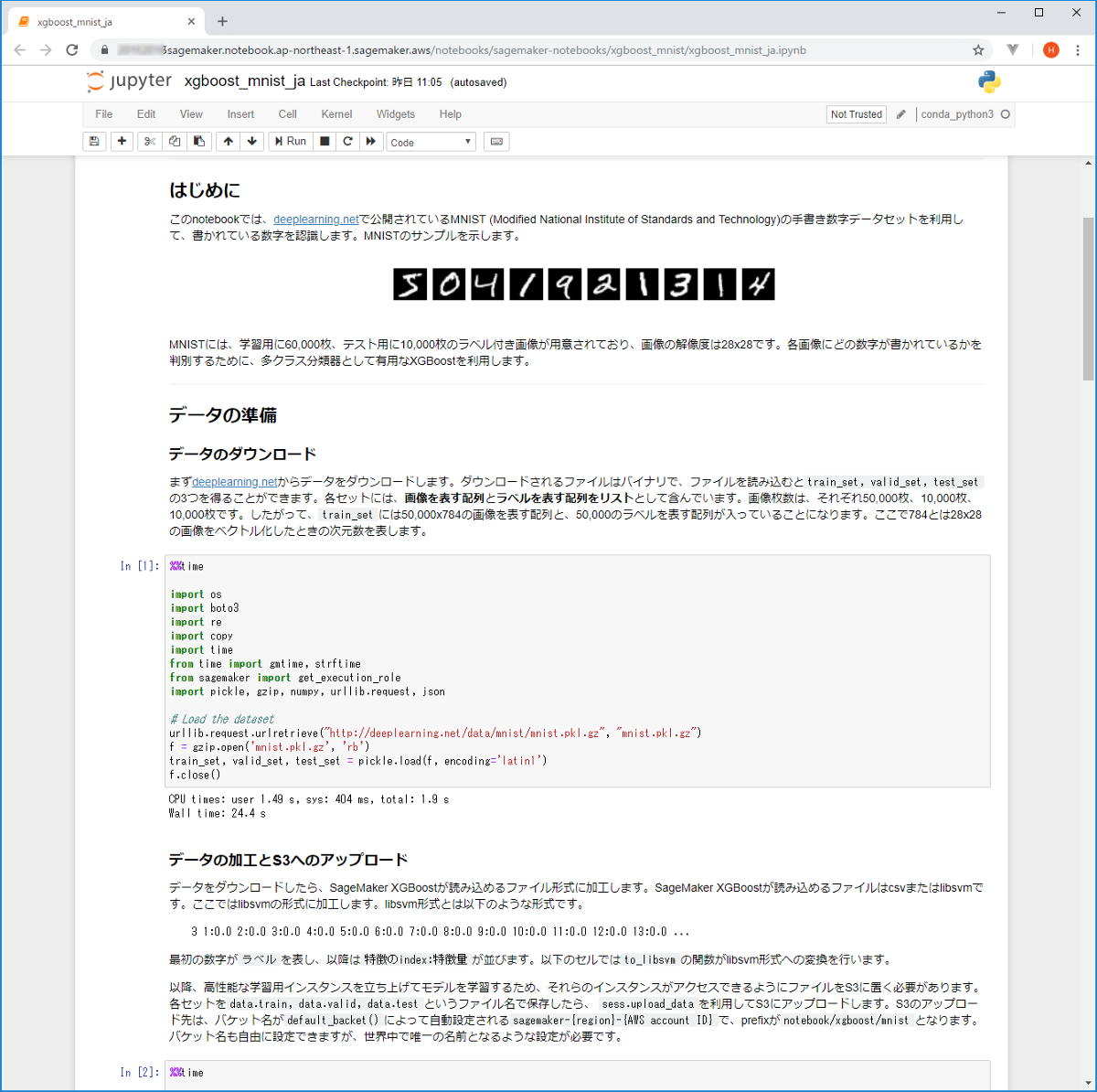
Amazon SageMaker の Jupyter Notebook
2. 開発したモデルを用いた学習 について、 SageMaker では各機械学習フレームワークを薄い層でラップしており、どのフレームワークを使用する場合でも概ね
# 使用する Dockerイメージを選択
containers = {‘ap-northeast-1’: ‘501404015308.dkr.ecr.ap-northeast-1.amazonaws.com/xgboost:latest’}
# 使用する Dockerコンテナのスペック、数を指定
xgb = sagemaker.estimator.Estimator(containers[boto3.Session().region_name],
role,
train_instance_count=1,
train_instance_type=’ml.m4.4xlarge’,
output_path=’s3://{}/{}/output’.format(bucket, prefix),
sagemaker_session=sess)
# ハイパーパラメータの指定
xgb.set_hyperparameters(eta=0.1,
objective=’multi:softmax‘,
num_class=10,
num_round=25)
# 学習の実行
xgb.fit({‘train’: train_input, ‘validation’: valid_input}, job_name = training_job_name)
の流れで学習を実行することができます。
ハンズオンではただ流れに沿って実行するだけですが、例えば MNIST という手書き文字識別の学習を TensorFlow で 10,000件のデータを対象に実行すると、通常スペックの PC で 1時間ぐらい平気で要したりします。
SageMaker は Dockerコンテナのスペック、数を指定して学習を分散実行できるので、データ・サイエンティストの方からすれば感動するほどの速さ(数分)で学習を完了させることができます。 AWS の知識が乏しくても Estimator にインスタンス・タイプとインスタンス数の指定パラメータを渡すだけなので、モデル開発のサイクルを早く回して、どんどん精度を改善していくことができます。
3. 推論の実行について、SageMaker では
xgb_predictor = xgb.deploy(initial_instance_count=1, instance_type=’ml.m4.xlarge‘)
のように 1行実行するだけで 推論を実行する API(エンドポイント)を作成し、インターネット上に公開することができます。
開発した機械学習のモデルを使用して推論を実行したいアプリケーションからは
result = boto3.client(‘sagemaker-runtime’).invoke_endpoint(
EndpointName='<deployで作成したエンドポイントの名前>’,
Body=<入力値>,
ContentType=’text/csv’
)
のように InvokeEndpoint するだけで推論の結果を得ることが出来ます。
(2. 学習においては、学習が完了した時点で使用した Docker コンテナは削除されますが、エンドポイントを作成した場合は削除するまで Docker コンテナが動いており料金がかかり続けます。)
いかがだったでしょうか。
AWSJ 亀田さんの解説によれば、SageMaker の Sage とは、英語の “賢者” が語源とのこと。使いこなすには機械学習フレームワークや数学、Python の知識が必要ですが、
1. モデルの開発(データの入手、クレンジング、変換を含む)
2. 学習の実行
3. 推論の実行
の流れが統一されておりシンプルになっているので、門外漢のエンジニアでも Jupyter Notebook の記述内で何を行っているか掴みやすくなっていると思います。
沖縄はどうだったかというと、ちょうど台風に見舞われ、最終日の帰る段になってようやく太陽を見ることができた感じで、大阪の方がずっと酷暑でした。
写真も沖縄では全く撮らなかったので、代わりに この週末に行ってきた Python合宿の琵琶湖岸の写真を貼っておきます。

Python合宿もずっと天気が悪く、最終日の朝に少し晴れたくらい
Python 合宿で LTさせていただいた資料も添付しておきますので、よろしければご覧ください。